概述(Summarize)
引擎初次运行时,会在当前目录内生成一个config.yaml 文件,该文件中的配置项可以直接左右引擎在运行时的状态。通过调整配置中的各种参数,可以满足不同场景下的需求。
在修改某项配置时,请务必理解该项的含义后再修改,否则可能会导致非预期的情况。
并发(Concurrent)
xray 基于 Go 编写,在 Go 语言中用户层级里没有线程的概念,但拥有一个比线程更加 强劲,更加好用的并发模型 —— Goroutine。这里的并发也基本指代的是同时在进行漏洞扫描的 Goroutine 的数量。 看起来有些拗口,我们可以用更简单的方式来理解这个概念。假设一个请求在整个扫描流程中需要被 100 个插件扫描且每个插件的执行时间为1秒钟, 倘若我们设置了并发为 50,那么只需要 2s 就能执行完所有的插件;如果设置并发为 20,那么就需要 5s 才能执行完所有插件。实际上,xray 在插件执行层面就是我们在操作系统中学习到的“生产者消费者模型”。 在配置文件中可以用下面的配置改变漏洞探测的 worker 数量:HTTP
对于 web 扫描来说,http 协议的交互是整个过程检测过程的核心。因此这里的配置将影响到引擎进行 http 发包时的行为。漏洞扫描用的代理:proxy
漏洞扫描用的代理:proxy
配置该项后漏洞扫描发送请求时将使用代理发送,支持 如果代理需要认证,可以使用下面的格式
http, https 和 socks5 三种格式,如:http://user:password@127.0.0.1:1111多代理配置
多代理配置
在漏洞扫描的时候,可能想不同的域名使用不同的代理,设置多个代理切换等,可以通过
proxy_rule 字段来配置。需要注意的是,proxy 配置将优先于本配置。- match: 请求的 url 的主机名如果匹配,就使用本条规则。
- 如果是
*,则代表可以匹配所有。所以一定要将*放在最后面,上面没有匹配到的域名都将使用这个配置。 - 如果没有任何一条可以匹配,这个请求将不会使用代理。
- addr: 代理服务器的地址,同
proxy的配置。 - weight: 代理服务器的权重,如果
servers中配置了多个代理服务器,设置权重可以均衡负载,比如权重是3:7,则代表每 10 个请求,有 3 个选择 server1,有 7 个选择 server2。要注意的是,这里是 round bin 算法,前 3 个一定发往 server1,后面 7 个一定发往 server2,然后继续循环,不是每个请求都是基于权重随机的。
限制发包速度:max_qps
限制发包速度:max_qps
默认值 500, 因为最大允许每秒发送 500 个请求。一般来说这个值够快了,通常是为了避免被ban,会把该值改的小一些,极限情况支持设置为 1, 表示每秒只能发送一个请求。
其他配置项
其他配置项
对照配置文件的注释好好理解下应该就能懂,如果不懂就不要改了。
插件(Plugins)
插件配置这一部分对应于配置文件的 plugins 部分。这一部分的每个配置项的 key 是插件名称,value 是与该插件相关的配置。 每个部分的结构大致如下enabled 即为是否启用插件, 其它的配置如果有,则是当前插件的一些特殊配置。鉴于配置文件本身已经有很多注释,这里不做赘述,仅对几个比较特殊的配置展开说明下。
xss
xss
ie_feature如果此项为 true,则会将一些只能在 IE 环境下复现的漏洞爆出来,小白请不要开。主要包括 expression xss、hidden tag xss、utf-7 和 content type sniffing 导致的 xss (参考链接 中的3. json)。include_cookie如果此项为 true, 则会检查是否存在输入源在 cookie 中的 xss
dirscan
dirscan
depth深度限制dictionary配置目录字典, 需要是绝对路径, 配置后将与内置字典合并
depth 是探测深度, 默认为 1, 即只在 URL 深度为 0, 和深度为 1 时运行该插件(前提是启用了该插件)定义 http://example.com/,深度为 0,定义 http://example.com/a/, 深度为 1。 在这种配置下,dirscan 将对http://example.com/ 和 http://example.com/a/ 做两次扫描,如果存在 http://example.com/a/example.zip 那么就能将其扫描出来。sqldet
sqldet
下面这个选项很危险,开启之后可以增加检测率,但是有破坏数据库数据的可能性,请务必了解工作原理之后再开启
dangerously_use_comment_in_sql允许检查注入的时候使用注释
phantasm
phantasm
phantasm 是 xray 的 poc 框架,在其下运行着许多 yaml 和 go 写的 poc,用户可以通过该模块编写自己的 poc 并让 xray 加载,具体见后续 自定义POC语法这里我们先介绍一下它的两个重点配置:上述配置的意思是加载
exclude_poc 用于去除加载哪些 poc。一个常见的 case 是如果发现某些 poc 误报比较多,想暂时禁用掉(并反馈给 xray),那么就可以在这一个配置中加上 poc 的名字,比如:include_poc 是用于加载本地的 poc 的配置,最好指定绝对路径,且同样支持 glob 语法。一个稍微复杂的情况是将这两个搭配起来使用,比如:/home/poc/ 目录下所有符合 *good-poc* 这个pattern 的poc,同时去掉同样目录下的 poc-fake-good-pocpoc_tags 是用于对内置的POC进行打标签,poc-yaml-test为poc的name,["HW", "ST"]为该POC的标签。使用示例如下:
./xray ws --tags ST,HW
这个时候,xray将会加载带有ST标签的POC。注:—tags可以与—level,—poc同时使用xstream
xstream
在注:如果你发现
xstream模块中,有一个特殊选项:full一般情况下xml请求是通过POST方法的Body发送,但特殊情况下可能会通过普通的某个参数发送。由于这种情况需要发送大量的数据包,所以默认关闭。如果你确定要使用这种测试方法,可以设置full参数为trueXStream模块的PoC和对应CVE不符,这是正常情况。XStream历史上有很多的CVE漏洞,我们的检测逻辑是当某一个版本存在多个CVE漏洞时,只要能够检测到其中一个漏洞就会输出当前版本存在的所有漏洞由于我们使用反连来确认XStream漏洞,所以该模块几乎不会产生误报被动代理(Mint)
代理启用密码保护
代理启用密码保护
对应于
auth 中的配置。xray 支持给代理配置基础认证的密码,当设置好 auth 中的 username 和 password 后,使用代理时浏览器会弹框要求输出用户名密码,输入成功后代理才可正常使用。限制允许使用该代理的 IP
限制允许使用该代理的 IP
配置中的 留空则允许所有地址访问,如果来源 IP 没有在配置的地址内,使用者会显示这样的错误:
allow_ip_range 项可以限制哪些 IP 可以使用该代理。支持单个 IP 和 CIDR 格式的地址,如:限制访问的端口、路径、Query Key等
限制访问的端口、路径、Query Key等
队列长度配置
队列长度配置
max_length。xray 将每 10s 打印一下当前任务队列长度,一旦堆积的数量达到 max_length,代理将会 “卡住”,新请求无法通过,等待队列中的请求被处理后再继续生效。默认配置的 10000 表示最多允许堆积 10000 个请求。如果发现队列长度经常变满,可能是扫描速度太慢,可以尝试减少请求超时的时间和增加最大并发请求数,详见 http 配置章节。如果 max_length 设置的过大,会造成 xray 内存占用过大,甚至可能会造成内存不足 OOM 进程崩溃。比如我们假设一个 http 请求加响应为 20kb,那 3000 个请求理论上内存占用至少为 60Mb,实际场景下可能会比理论值还要大很多。更多信息可以参见扫描速度。代理请求头配置:proxy_header
代理请求头配置:proxy_header
via 头和 X-Forwarded-* 系列头。如果在请求中就已经存在了同名的 HTTP 头,那么将会追加在后面。比如 curl http://127.0.0.1:1234 -H "Via: test" -H "X-Forwarded-For: 1.2.3.4" -v,后端实际收到的请求将会是代理的代理:upstream_proxy
代理的代理:upstream_proxy
假如启动 xray 时配置的 listen 为 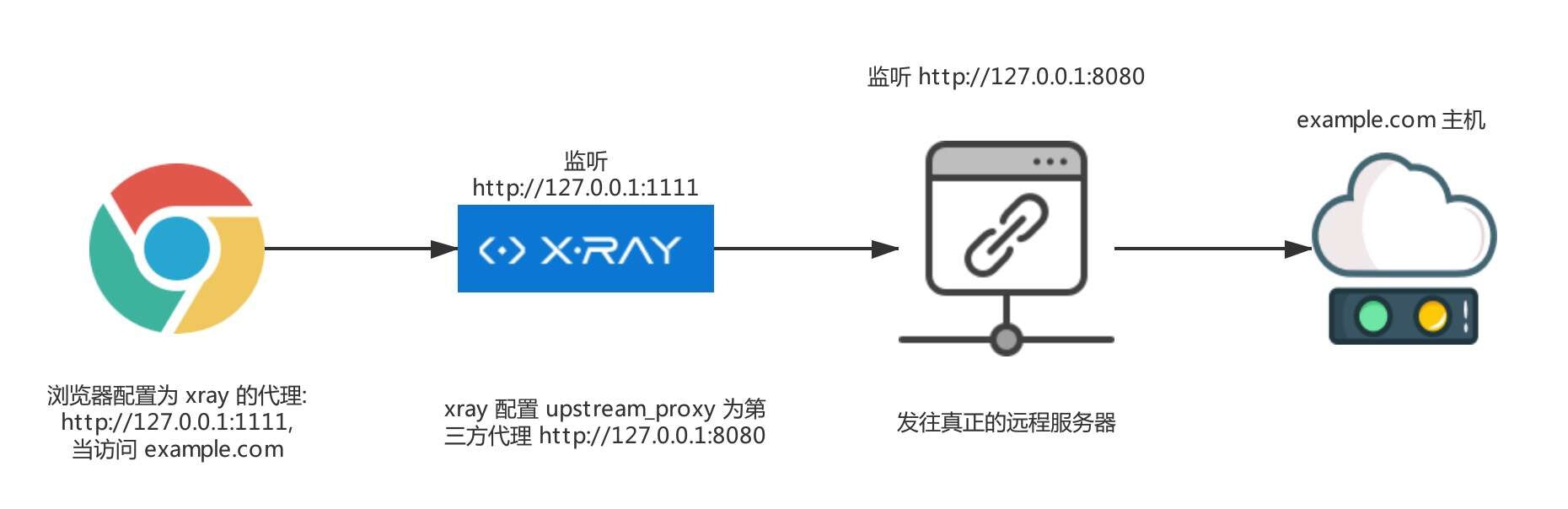
127.0.0.1:1111,upstream_proxy 为 http://127.0.0.1:8080, 那么浏览器设置代理为 http://127.0.0.1:1111,整体数据流如下:基础爬虫(Basic Crawler)
反连平台(Reverse)
反连平台常用于解决没有回显的漏洞探测的情况,最常见的应该属于 ssrf 和 存储型xss。渗透测试人员常用的 xss 平台就是反连平台。 如果你不理解上面这句话,可以先去学习一下这两个漏洞,否则这篇文章也是看不懂的。 在 xray 中,反连平台默认不启用,因为这里面有些配置没有办法自动化,必须由人工配置完成才可使用。需要反连平台才可以检测出来的漏洞包括但不限于:- ssrf
- fastjson
- s2-052
- xxe 盲打
- 所有依赖反连平台的 poc
场景分析
场景分析
场景1 - xray 和目标可以使用 ip 双向互联
假设 192.168.1.2 是 xray 所在机器的地址http://192.168.1.2:xxx/xxx,xray 会受到这样的“反连”回来的请求,并将漏洞结果展示出来。场景2 - xray 和目标可以使用 ip 双向互联,但 listen 的地址和目标反连访问的地址不一样
这种情况经常出现在云主机中,比如腾讯云的 linux 机器网卡地址时 10.xxx,但实际公网假设是 221.xxx${port} 是一个预定义的宏,在运行时将被替换为实际监听的端口, 当然你也可以使用这种方式固定监听的端口:场景3 - 独立部署反连平台
上面两种场景说的都是在扫描时临时启动一个反连平台,实际上单独部署一个反连平台更加常见,比如上面说的 xss 平台其实就是单独部署的一个反连平台。xray 自带了一个reverse 命令,可以启动反连平台作为一个远程服务运行,给多个客户端使用。db_file_path 和 token,前者用于存储数据,后者用于服务端和客户端通信的秘钥。一个示例的服务端配置是:管理界面
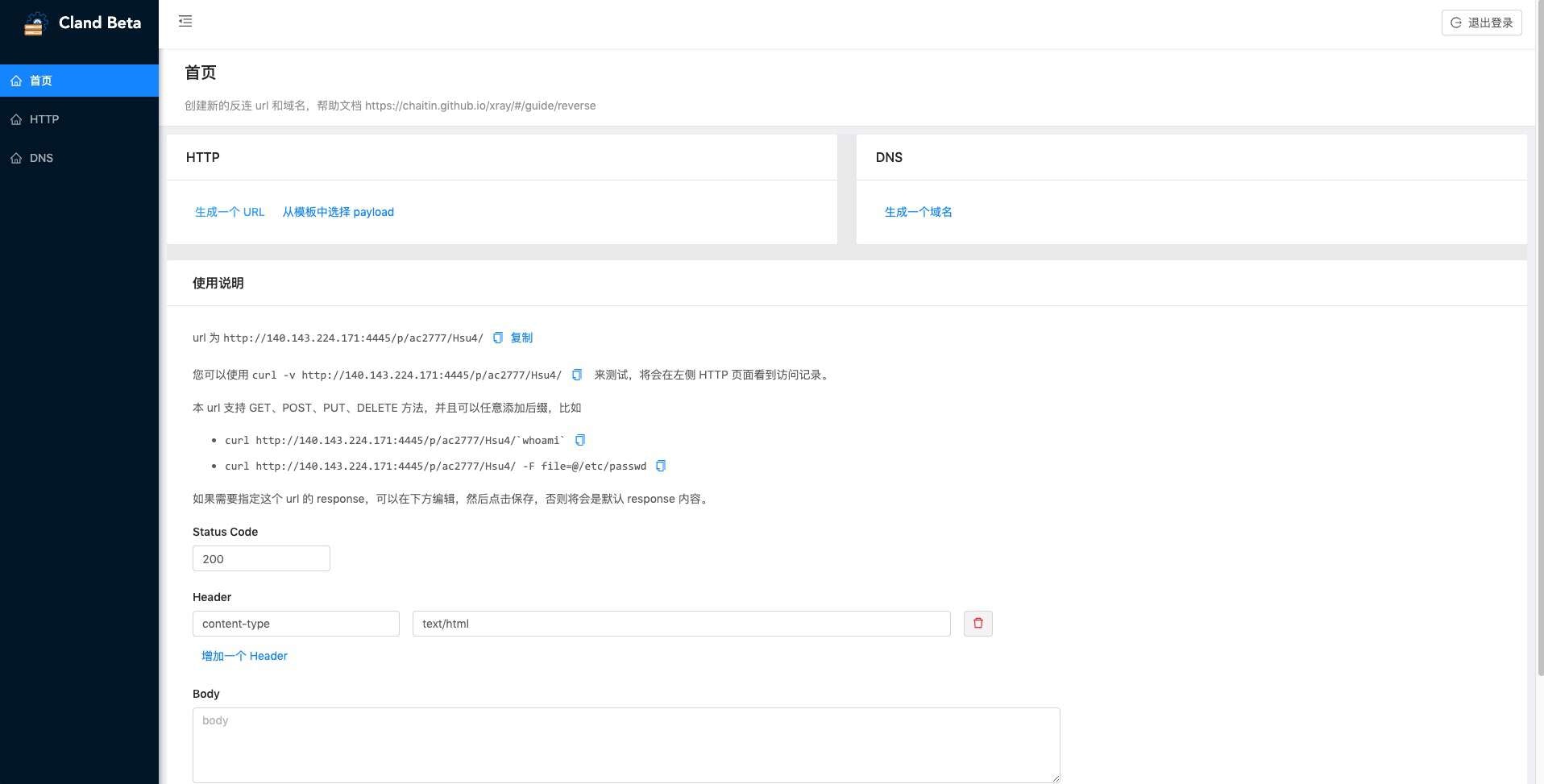
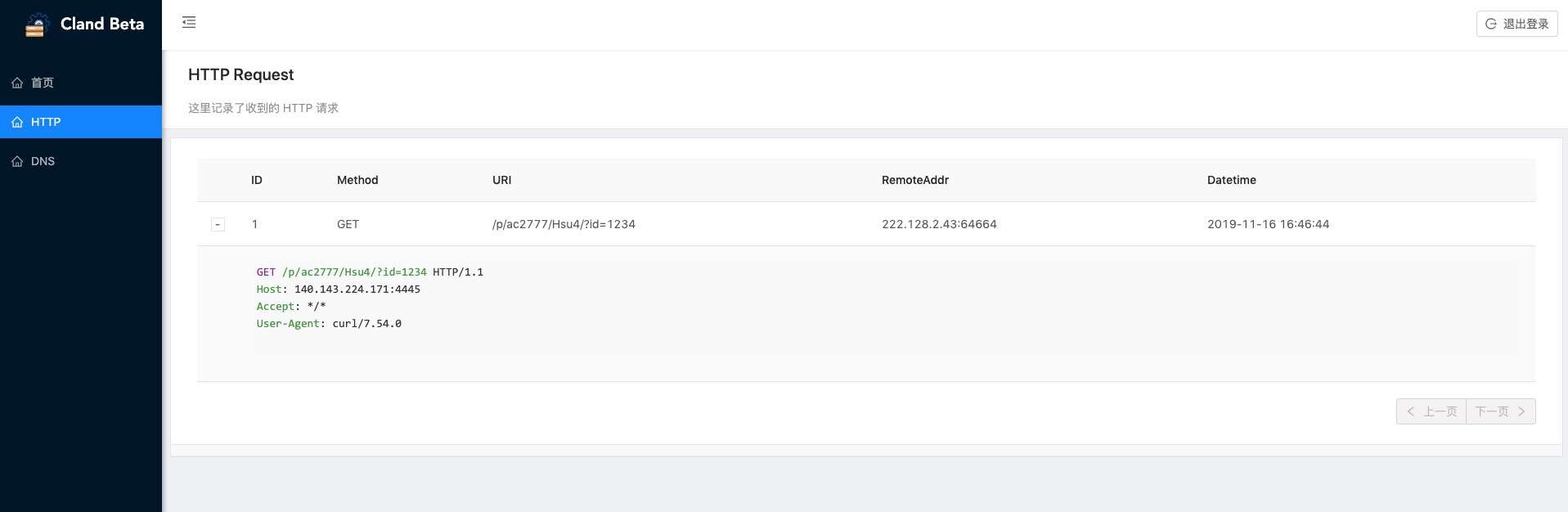
管理界面
反连平台贴心的内置了一个管理界面,可以访问反连平台 http 地址,url 为
/cland/。功能包括- 生成自定义 url,并记录访问记录
- 生成自定义域名,并记录解析记录
-
使用平台预制 payload,记录抓取的数据
尝试一下!
尝试一下!
我相信你看了上面的配置依然是云里雾里,不妨自己试一下!一个很好的测试例子是 fastjson,从 vulhub 上拉取一个镜像并启动,配置好你的反连平台看下能不能扫出吧!
DNS 相关
DNS 相关
详细配置内容请参考如何部署xray反连平台
- listen_ip 监听的 ip
- domain 在 dns 查询的时候的一级域名,默认为空,将使用随机域名。
- resolve 的配置类似常见的 dns 配置,如果反连平台收到配置的域名的解析请求,将按照配置的结果直接返回。
- is_domain_name_server 如果上述域名的 ns 服务器就是反连平台的地址,那么直接使用
dig random.domain.com就可以让 dns 请求到反连平台,否则需要dig random.domain.com @reverse-server-ip指定 dns 服务器才可以。本配置项是指有没有配置 ns 服务器为反连平台的地址,用于提示扫描器内部 payload 的选择。
子域名(Subdomain)
更新(Update)
xray 内置了一个简单的更新检查机制,会在每次启动的时候检查有无新的版本发布,如果有更新将在界面上显示最新的 release notes。 如不需要该机制,可以通过下列方法禁用: 在config.yaml 中添加如下配置即可禁用更新检查: